Domain Name System (DNS) is a popular way to steal sensitive information from enterprise networks and maintain a covert tunnel for command and control communications with a malicious server. Due to the significant role of DNS services, enterprises often set the firewalls to let DNS traffic in, which encourages the adversaries to exfiltrate encoded data to a compromised server controlled by them.
To detect low and slow data exfiltration and tunneling over DNS, in this research, we develop a two-layered hybrid approach that uses a set of well-defined features. Because of the lightweight nature of the model in incorporating both stateless and stateful features, the proposed approach can be applied to resource-limited devices. Furthermore, our proposed model could be embedded into existing stateless-based detection systems to extend their capabilities in identifying advanced attacks.
We are releasing CIC-Bell-DNS-EXF-2021, a large dataset of 270.8 MB DNS traffic generated by exfiltrating various file types ranging from small to large sizes. We leverage our developed feature extractor to extract 30 features from the DNS packets, resulting in a final structured dataset of 323,698 heavy attack samples, 53,978 light attack samples, and 641,642 distinct benign samples. The experimental analysis of utilizing several Machine Learning (ML) algorithms on our dataset shows the effectiveness of our hybrid detection system even in the existence of light DNS traffic.
Table 1 shows the features extracted to detect data exfiltration over DNS. Generally, the features are divided into two large groups: stateless and stateful. Stateless features are independent of time-series characteristics of queried domains or hosts’ DNS activity and can be derived from individual DNS query packets. This reduces the overhead in computing these attributes in real-time. In contrast, stateful features consider a range of queries in a time window and thus inflict a high computational cost on the detection system. However, stateful detection allows scanning DNS logs for a long period of time and therefore, can deal with low and slow DNS attacks.
| Feature | Feature name | Description | State |
|---|---|---|---|
| F1 | rr_type | The type of resource record, e.g., A, TXT, MX, ... | stateful |
| F2 | rr_count | The count of entries in each section: question, answer, authority, and additional | stateful |
| F3 | rr_name_length | The resource record name length | stateful |
| F4 | rr_name_entropy | The entropy of resource record name | stateful |
| F5 | rr_type_frequency | Number of packets of a given resource record type for a given domain over the total number of packets for that domain (where qtype is A, AAAA, CNAME, MX, NAPTR, NS, NULL, SOA, TXT, STAR, SRV, and PTR; example feature names: A_Frequency, TXT_Frequency, ... | stateful |
| F6 | rr | Distribution of A and AAAA resource records, i.e., the rate of A and AAAA records per domain in window τ | stateful |
| F7 | distinct_ns | Number of distinct Name Server (NS) records, i.e., the total number of NSs resolved in DNS Database (DNSDB) | stateful |
| F8 | a_records | Number of distinct A records, i.e., the total number of IP addresses resolved in DNSDB | stateful |
| F9 | unique_country | Distinct country names for a given domain in window tau | stateful |
| F10 | unique_asn | Distinct Autonomous System Number (ASN) values in window τ | stateful |
| F11 | unique_ttl | Distinct Time-to-Live (TTL) values in window τ | stateful |
| F12 | distinct_ip | Distinct IP values for a given domain in window τ | stateful |
| F13 | distinct_domains | Distinct domains that share the same IP address that resolve to a given domain in window τ | stateful |
| F14 | reverse_dns | Reverse DNS query results for a given domain in window τ | stateful |
| F15 | ttl_mean | The average of TTL in window τ | stateful |
| F16 | ttl_variance | The variance of TTL in window τ | stateful |
| F17 | FQDN_count | Total count of characters in FQDN | stateless |
| F18 | subdomain_length | Count of characters in subdomain | stateless |
| F19 | upper | Count of uppercase characters | stateless |
| F20 | lower | Count of lowercase characters | stateless |
| F21 | numeric | Count of numerical characters | stateless |
| F22 | entropy | Entropy of query name: H(X)=-∑_(k=1)^N▒〖P(x_k)log_2〖P(x_k)〗 〗, X=query name, N=total number of unique characters, P(x_k )=the probability of the k-th symbol | stateless |
| F23 | special | Number of special characters; special characters such as dash, underscore, equal sign, space, tab | stateless |
| F24 | labels | Number of labels; e.g., in the query name "www.scholar.google.com", there are four labels separated by dots | stateless |
| F25 | labels_max | Maximum label length | stateless |
| F26 | labels_average | Average label length | stateless |
| F27 | longest_word | Longest meaningful word over domain length average | stateless |
| F28 | sld | Second level domain | stateless |
| F29 | len | Length of domain and subdomain | stateless |
| F30 | subdomain | Whether the domain has subdomain or not | stateless |
In this section, we explain an overview of our proposed approach to determine whether a DNS query is normal or attack. We aim to design a lightweight approach, so it could be deployed in resource-constrained devices. As shown in Figure 1, we provide a two-layered approach in which the stateless features are extracted from the incoming DNS traffic in window τ (window of packets), and then the structured data goes through a trained classifier. The classifier output probability is then divided into three bins, i.e., [0-0.4[, [0.4-0.7[, [0.7-1] to help the classifier score each input sample in window τ as benign, suspicious, or malicious.
If the ratio of the suspicious samples in window τ, i.e., r_sus^τ, exceeds the threshold δ, the whole traffic window is re-analyzed using stateful features to let the trained classifier on stateful features decide about the whole window τ. Otherwise, the input sample is either identified as benign for which the DNS traffic keeps on flowing or is detected as attack for which we terminate the DNS traffic.
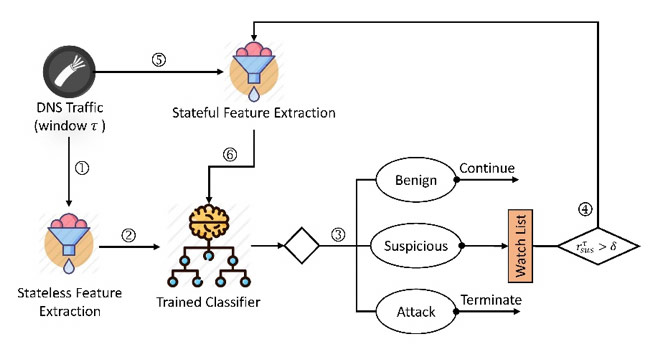
Stateful features could be leveraged as supplementary material to consider the DNS traffic in case a noticeable portion of the packets in a packet window is suspicious, which could be further investigated. Using stateful features, the classifier determines the maliciousness degree of the whole window and not the individual packet.
Figure 2 explains how data exfiltration attack using DNS is run on the Canadian Institute for Cybersecurity (CIC) testbed. The data is encoded on the client-side (victim's side) and piggy-backed on DNS requests to the DNS server set as the name server of the attacker's machine. Practically, the server-side (attacker's side) acts as a malicious DNS server and receives the encoded file. The file is then decoded to see the content.
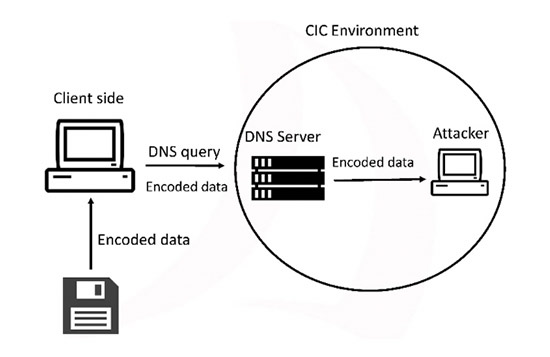
We use the DNSExfiltrator tool, publicly available on GitHub, which helps us for conveying a file over a DNS request covert channel. We also registered a domain name, namely cicresearch.ca and set the NS record for that domain to point to the attacker's server that will run the server-side script.
In the DNSExfiltrator tool, the encoding algorithm and the throttling time are set to base64URL and 500 MS, respectively. The maximum size in bytes for each DNS request is set to the default value (255 bytes) and the maximum size in chars for each DNS request label (subdomain) is set to default (63 characters).
We used DNS active data collection method for collecting DNS data. We collected benign samples from Alexa top 1-million domains. For collecting DNS data exfiltration attack traffic, we conducted the attack in two categories of light file attack and heavy file attack in five consecutive days. There are six file types in each heavy and light category including, audio, compressed, .exe, image, text, and video. The size of the light file category ranges from 15KB to 924KB while the size of heavy files ranges from 4.5 MB to 26.9MB. For capturing the benign traffic, we sent HTTP requests to the collected domains' web server using a Python script and dump the packets with an OK response. To acquire a real-world generated dataset, we use distinct benign domains on each consecutive day.
The attack scenario is as follows:
All the benign and attack traffic were captured using TCPDump on the victim's side and labeled according to their timestamps. We captured a total of 20.7MB, 147.6MB, and 102.5MB DNS packets for heavy, light, and benign traffic.
We then applied our developed DNS feature extractor package to extract 14 stateless and 16 stateful features from all .PCAP files. The benign/attack ratio for each pair of heavy-stateful, heavy-stateless, light-stateful, and light-stateless is 60/40%.
Table 2 shows the statistics of the captured DNS packets and final structured CSV files in three categories of benign, light attack, and heavy attack. Each row in our structured dataset depicts a timestamped DNS packet along with the 30 extracted features. To keep the benign/attack ratio, we injected the benign packets on the first day to benign packets on the light attack day, i.e., light-benign, and similarly to the benign packets on the three heavy attack days, i.e., heavy-benign.
| Category | #Stateful | #Stateless | #DNS Packets |
|---|---|---|---|
| Heavy Attack | 72,028 | 251,670 | 147.6MB |
| Heavy-Benign | 156,014 | 402,767 | 90.3 MB |
| Light Attack | 11,295 | 42,683 | 20.7MB |
| Light-Benign | 109,766 | 281,164 | 62.4MB |
In the preprocessing step, we remove the timestamps from the features to prevent ML overfitting problems. We sanitize the data by replacing nan values with zero. Furthermore, we encode the stateful and stateless categorical features. The stateful categorical features include, rr_type, distinct_ip, unique_country, unique_asn, distinct_domains, reverse_dns, and the stateless categorical features consist of longest_word and sld. We also substitute the unique_ttl lists with the average of the TTL values in each list.
For the parameter setting, the window size τ is set to 100 packets and the sliding window step s is set to 100. We choose a small value for τ to avoid a high false-positive rate. Based on Figure 1, if the stateless classifier detects even one packet malicious, we dump the whole packet window. Therefore, setting the window size to a fairly large value might result in shutting down a noticeable portion of the benign DNS traffic which is not desirable in a real-world situation. The threshold for the ratio of the suspicious samples, i.e., δ, is also considered as 0.4.
We develop five classification algorithms using Scikit-learn library in Python including Gaussian Naive Bayes (GNB), Random Forest (RF), Multi-layer Perceptron (MLP), Support Vector Machine (SVM), and Logistic Regression (LR). We set the train-test split ratio to 70%-30% and shuffle the entire dataset before splitting. Experimental results proved that RF outperforms other algorithms in detecting light and heavy attacks. A key advantage of the proposed lightweight strategy is the capability to detect DNS data exfiltration attacks in resource-constrained devices in a better manner.
You may redistribute, republish, and mirror the CIC-Bell-DNS-EXF-2021 dataset in any form. However, any use or redistribution of the data must include a citation to the CIC-Bell-DNS-EXF-2021 dataset and the following paper:
Samaneh Mahdavifar, Amgad Hanafy Salem, Princy Victor, Miguel Garzon, Amir H. Razavi, Natasha Hellberg, Arash Habibi Lashkari, “Lightweight Hybrid Detection of Data Exfiltration using DNS based on Machine Learning”, The 11th IEEE International Conference on Communication and Network Security (ICCNS), Dec. 3-5, 2021, Beijing Jiaotong University, Weihai, China.
If you are interest in CIC-Bell-DNS-EXF-2021, you may also be interested in the BCCC-CIC-Bell-DNS-2024 dataset made available by our colleagues at the Behaviour-Centric Cybersecurity Center, York University.